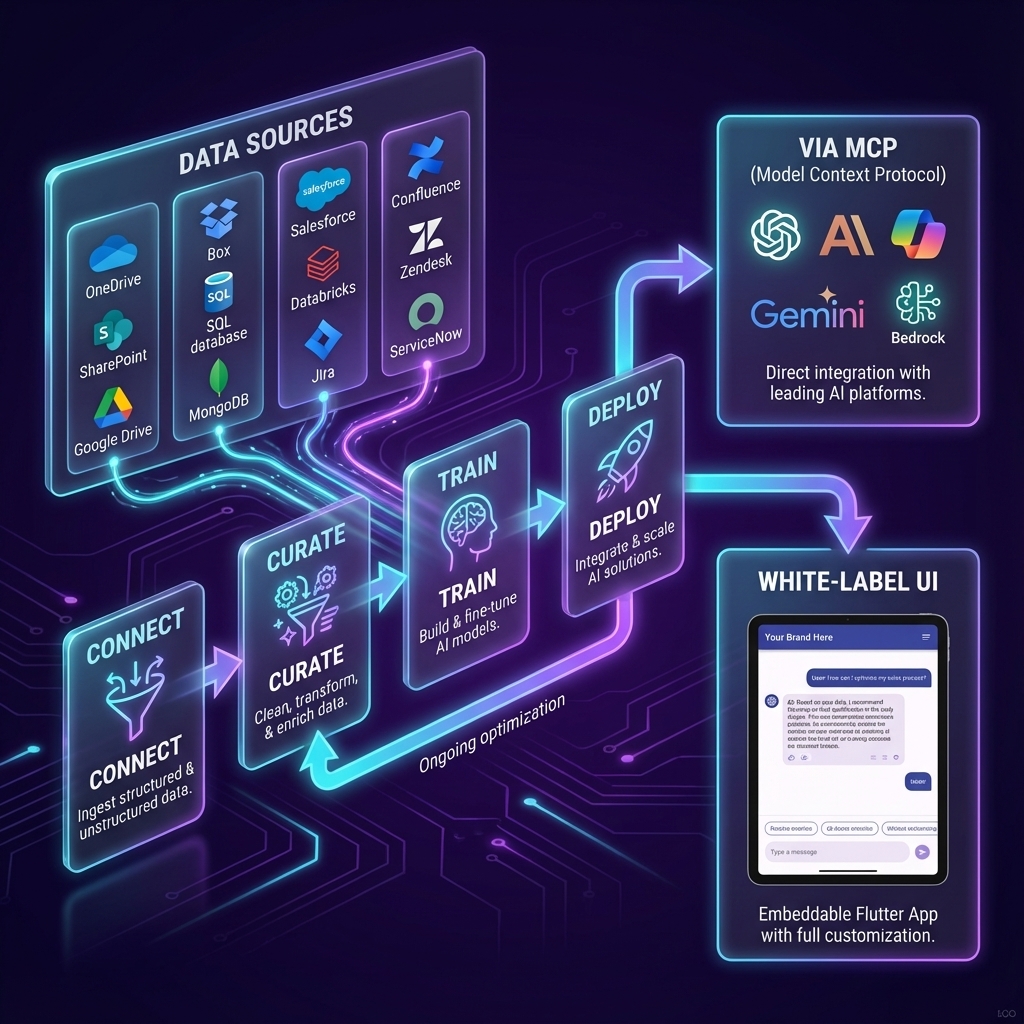
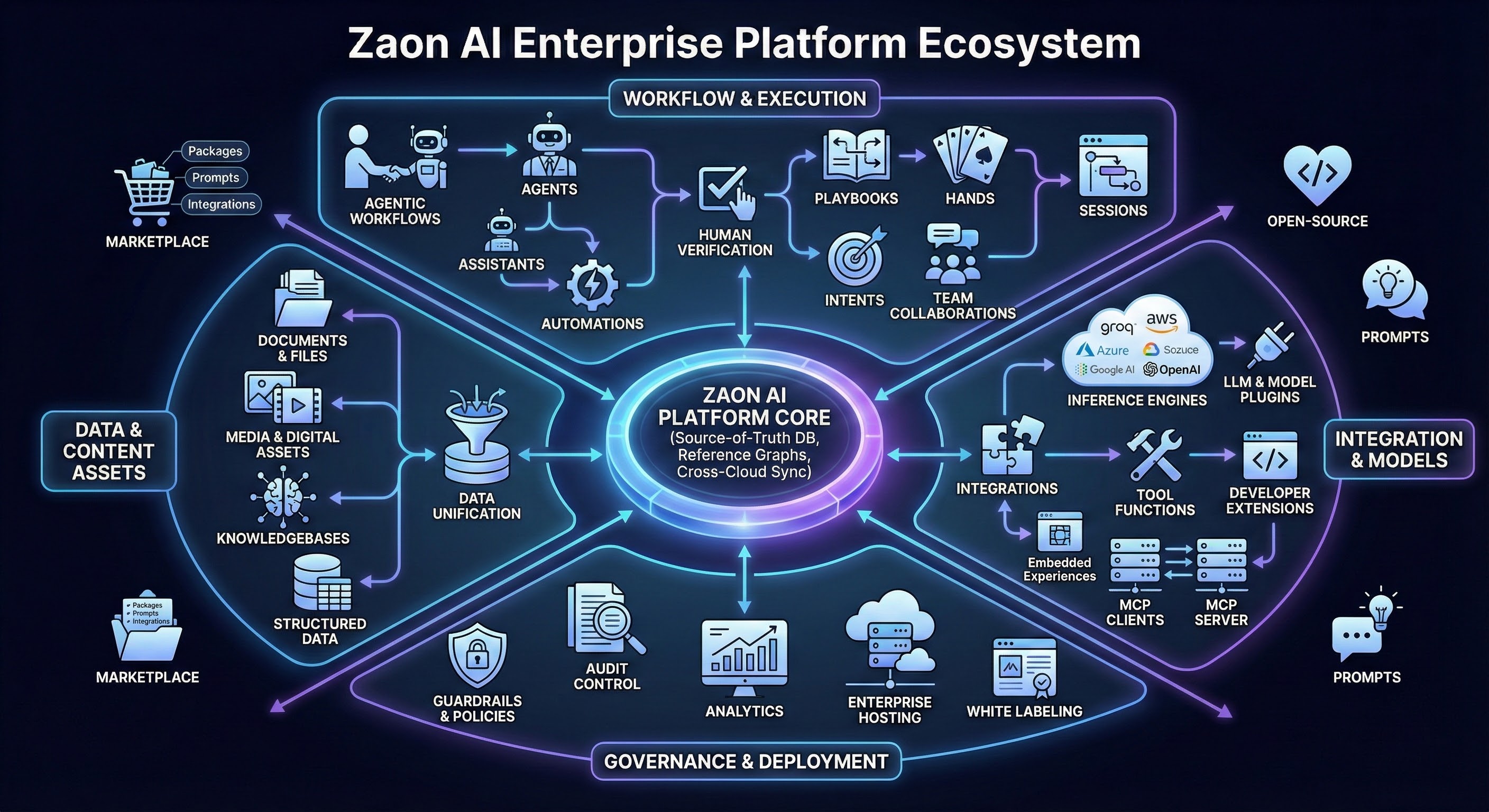
AI That Sales Teams Actually Trust.
Your Data. Your LLM. Your Terms. Zaon curates and verifies your sales knowledge to train team-specific LLMs — so every rep has instant, accurate answers that win deals. Securely deployed in your cloud.
Trusted by enterprises using:
AWS
Azure
Google Cloud
Oracle